The More You Do, The Closer You Get to Zero: My Two Days Hunting Alpha in a Prediction Market
- Published on
- ...
- Authors

- Name
- Huashan
- @herohuashan
An honest post-mortem of a quantitative failure: a +36% in a small sample, beaten back toward zero by t-statistics and the law of large numbers; and why much of homogeneous competition works the same way.
Prelude: A Place That Looks Like Easy Money
On Polymarket there's a type of market called "Bitcoin Up or Down," one round every 5 minutes: bet whether BTC will be up or down at the end of those 5 minutes compared to the open. Buy Up if it's rising, Down if it's falling; at settlement, winning contracts pay out $1 each, losers go to zero.
It looks tailor-made for "running a strategy": high frequency, extremely simple rules, and a public order book. My intuition was straightforward—if BTC has already moved clearly in one direction during the current 5 minutes, is the win rate higher if I bet in that same direction? That's momentum continuation.
So I spent two days writing scripts, running backtests, going live with real money, deploying to a cloud server, setting up monitoring and alerts. This article isn't a tutorial on how to make money—quite the opposite. It's a record of how I talked myself into "there's money to be made here," and how the math woke me up step by step.
If you only want the conclusion: this technical-momentum-plus-trend-following approach converges to zero the more you trade; after fees and slippage, it's more likely to go negative. This is what an efficient market normally looks like, not bad luck on my part.
The Sweet Trap: +36% in a Small Sample
I quickly found a "sweet spot" that made my heart race. When all of these conditions held at once:
- BTC's move in the current 5 minutes is between $30–$40 (momentum strong enough, but not extreme)
- Entry ask price < 0.65 (decent odds, not too expensive)
- Follow the 24-hour trend direction (Up in an uptrend, Down in a downtrend)
The backtest looked too good to be true:
| Segment | Samples | Win Rate | ROI |
|---|---|---|---|
| move 30–40 & ask<0.65 & trend-follow | 66 trades | 79% | +36% |
A 79% win rate, earning thirty-six cents on the dollar per cycle. My reaction, like most people's, was: "I found it."
Anyone who's done quant work should hear an alarm at this point: is 66 trades enough? Is that +36% real edge, or luck?
I Need a Referee: What t Is and Why t
To answer "is this luck," win rate and total profit don't qualify as referees:
- Total profit alone: a lucky streak of wins can make total profit look great, and fool you.
- Win rate alone: 79% sounds high, but if the payoff is terrible (e.g., you win a little each time but lose everything on a loss), high win rate can still lose money.
I need a metric that simultaneously accounts for "how much earned, how much variance, how many trades." That's the t-statistic.
It comes from one of the simplest questions in statistics—the one-sample t-test: I have a set of per-trade returns x₁, x₂, …, xₙ, and I want to know whether their true mean is actually 0 (0 means "no edge at all, pure gambling").
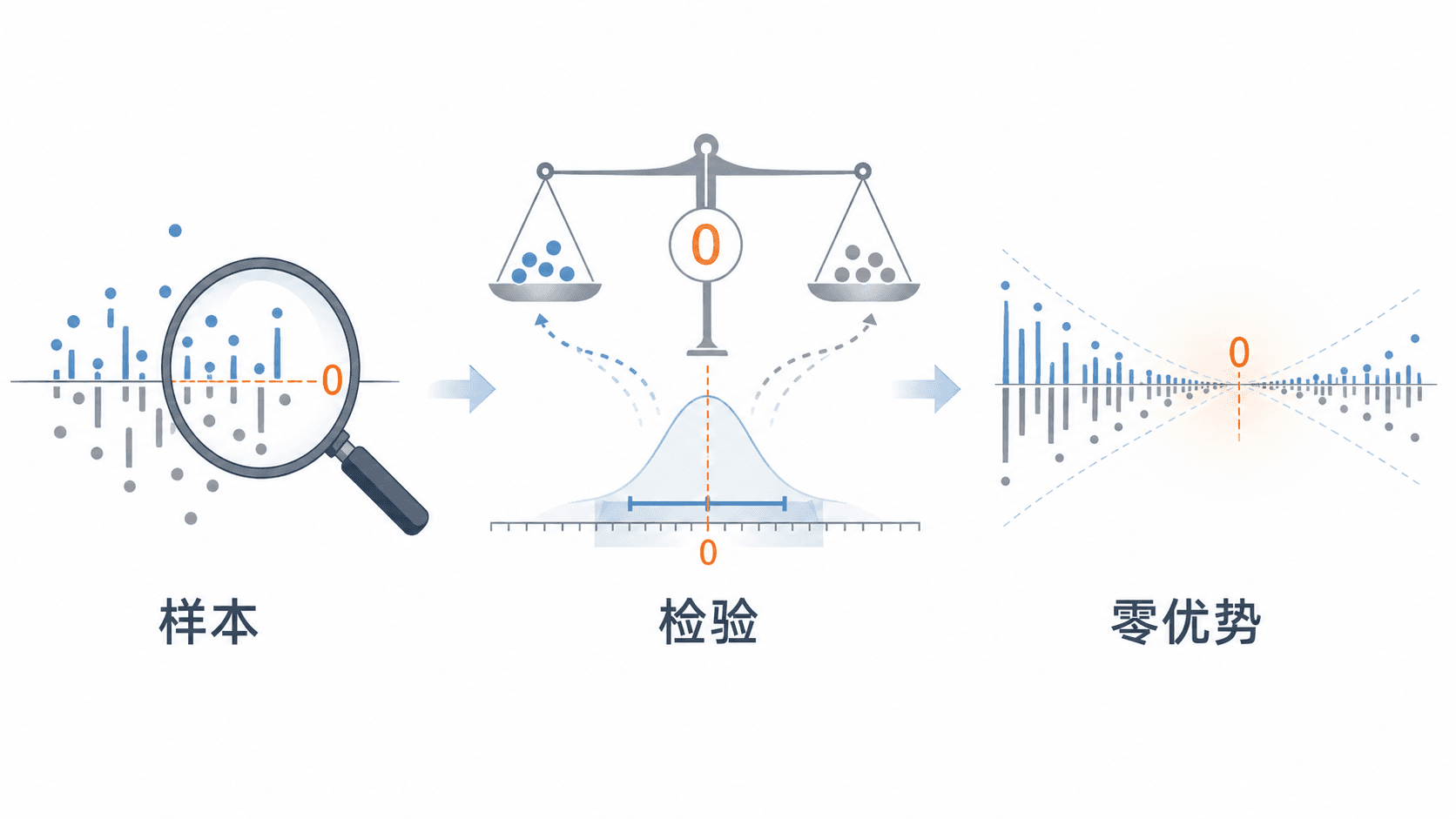
The definition of t is:
t = (sample mean − 0) / (sample standard deviation / √n)
= x̄ / (s / √n)
Breaking down the formula, each of the three parts does one job:
- Numerator
x̄(sample mean): how much you earn per trade on average. The more you earn, the larger t. sinside the denominator (standard deviation): how volatile your returns are. The more erratic the wins and losses, the smaller t—because high variance means "this positive result is more likely accidental."√ninside the denominator (square root of sample size): how many trades you've made. The more trades, the smaller the denominator and the larger t—the more samples, the more credible the same mean becomes.
In one sentence: t measures "the signal-to-noise ratio of this positive return." It penalizes variance, rewards sample size, and neatly separates "luck" from "skill."
The empirical threshold is |t| ≥ 2: roughly corresponding to 95% confidence, meaning "if the true mean were actually 0, the probability of getting a t this large purely by chance is less than 5%." If t < 2, we have no right to say 'this isn't luck.'
So what's t for that +36% sweet spot?
I ran 49 trades live with real money, overall t = 0.44.
0.44. A universe away from 2.
In other words: the books show a profit (the wallet climbed from $50 to $66 at one point), but statistically I cannot distinguish it from "pure-luck breakeven."
Down the Rabbit Hole: Various Attempts to Push t Up
A normal person would stop at t = 0.44. But I'm not normal—I went down the rabbit hole, twisting one knob at a time, trying to push t past 2.
First thought: add a stop-loss. Cut losers early, can I recover? I backtested every stop-loss distance on historical data. The result was counterintuitive:
On a high-win-rate strategy like this 79% one, stop-losses actually make total returns worse. Because the losses they save (about +$46) are far outweighed by the winners they accidentally kill (about −$86). High-win-rate strategies and stop-losses are naturally at odds—you mostly cut trades that "scare you mid-flight but end up winning."
Second thought: adjust the 24h trend filter. I noticed a weird phenomenon—the Up direction always made money, the Down direction always lost; should I only trade Up? But I quickly realized: because I added a 24h trend-following filter, direction and market regime are locked together. When BTC is falling, I can only take Down; when it's rising, only Up. So-called "Up makes money, Down loses" isn't a direction issue at all—it's "whether the market is easy to trade" disguised as a directional difference.
Third thought: adjust the ask threshold. Tightening entry to < 0.6, then < 0.55, did raise per-trade ROI (+36% → +44% → +65%). But there's a catch: while tightening, sample size collapsed (66 → 27 → 13 trades), and t dropped rather than rose. Because the denominator contains √n, when samples shrink, s/√n actually grows, and the slightly higher mean can't hold it up. More profit per trade ≠ more credible.
Fourth thought: cap the move size. I was once convinced that move > 40 was a "trap" and cutting it would help. Reality slapped me down—recent live losses came precisely from the 30–40 core, while move > 40 had only 4 trades total, a small historical sample that never changed. I was once again treating noise in a small sample as a pattern.
Each knob, viewed in isolation, had "some logic to it." But they all share one common feature—they're all built on small samples of a few dozen trades.
The Law of Large Numbers' Slap: The More You Do, The Closer to Zero
What really woke me up was a 2×2 table.
I decided to fully separate "direction" and "market regime" and look at the four combinations independently. First, in my cherry-picked small sample (move 30–40):
| 24h Up | 24h Down | |
|---|---|---|
| Take Up | +36% | +8% |
| Take Down | +7% | +38% |
Beautiful. The diagonal (trend-following) is +36%/+38%, the anti-diagonal (counter-trend) is +7%/+8%. "Trend-following works" seems like a closed loop; I almost believed it again.
Then I did the only correct thing: I expanded the sample. The same 2×2, but across all 714 trades:
| 24h Up | 24h Down | |
|---|---|---|
| Take Up | −2% | +1% |
| Take Down | +5% | +1% |
All four cells hovering right around 0.
That pretty +38% trend-following edge vanished into thin air the moment the sample grew.
Only at that moment did I truly understand what I'd been staring at for two days:
The larger the sample, the more results converge to the true expectation. The reason a small sample can produce +36% isn't because there's an edge there—it's because with few samples and high variance, it has plenty of freedom to deviate from 0 by chance. All the "optimization" I did was, in essence, fishing out the corners that happened to skew positive within the noise of a few dozen trades, then convincing myself that was a pattern.
This is the law of large numbers in its simplest and most brutal form: the more you do, the closer you get to the essence of the game. At least for the publicly visible momentum + trend-following signals I tested, that essence is: gross expectation is near zero, and net expectation is easily pushed negative by transaction costs.
This Is the Definition of an "Efficient Market"
Step back and this conclusion shouldn't be surprising at all.
BTC's 5-minute direction is a very nearly efficient-market scenario. All those obvious signals you can think of—how strong the momentum is, the 24h trend, the entry price—were already seen by everyone and priced into that ask.
The 0.62 you pay to buy Up already contains the market's full consensus on "it will go up." What you earn is never "whether the direction is right," but the tiny gap between "true probability" and "market price." If you don't have better information, faster execution, or a more unique pricing model than the market, that gap will easily be statistically indistinguishable from zero.

I later cross-checked with a full set of independent evidence, none of which met my standard for adding more real money:
- 49 live trades, t = 0.44
- In normal entry-price ranges, especially around ask 0.4–0.6, large-sample net expectation is negative
- None of the trend-filter parameter combinations pass out-of-sample testing at a tradeable level (OOS t ≥ 2 with sufficient sample size)
- Many "seemingly significant" small regions collapse once you expand the sample or move out of sample
- I turned every knob—stop-loss, trend, price, move size—and none of them saved the day
All this evidence points to the same period at the end of the sentence: this doesn't prove that the BTC 5-minute market can never have any edge, but it does prove that my retail-accessible technical-momentum-plus-trend-following method has not demonstrated a sustainable, tradeable edge.
Extension: Other Things Where Effort Converges to Zero
This whole experience led me to a bigger question: many things in real life work like this market. It's not that effort is useless—it's that when everyone is staring at the same scoreboard, using the same rules, chasing the same signal, effort first becomes a ticket, then a cost, and finally gets averaged away by competition.
A few very common examples:
First, chasing public trends to make content. Today some platform says short videos need a three-second hook, strong emotional titles, fixed rhythm editing; tomorrow everyone does it. The earliest adopters of the template may enjoy a bonus; once the template is widespread, algorithms, advertisers, and competitors will eat that bonus. The harder you work to follow the template, the closer you get to the platform's average. What might actually have positive expectation isn't "applying the template more aggressively," but having unique material, unique viewpoints, long-term trust, or assets you can compound into your own distribution.
Second, the certificate-and-resume arms race. When a certificate is scarce, it's a signal; once everyone has it, it becomes a barrier. Grinding problems, projects, and internships is certainly useful, but if everyone is doing the same set of actions, the result usually isn't that you get excess returns—it's that the bar rises for everyone. Effort doesn't disappear; it just shifts from "advantage" to "cost of not being eliminated."
Third, homogeneous platform businesses. Food delivery, ride-hailing, e-commerce, homestays, paid knowledge—as long as supply is highly homogeneous and traffic gateways are in the platform's hands, competition squeezes margins thin. You put in a bit more work, and platform commissions, ad bidding, price wars, and consumer comparison shopping will take away the extra gains. In the end everyone looks busy, but industry-average profit margins stay flat.
Fourth, chasing signals everyone can see in secondary markets. Trending topics, KOL calls, leaderboards, funding rates, simple technical indicators—the more public they are, the more easily they're priced in ahead of time. You're not trading the chart; you're trading against everyone who sees the same chart.
These scenarios share a common structure:
- Rules are public.
- Signals are public.
- Many participants.
- Outcomes are distributed by relative ranking.
- Costs are real.
In this kind of structure, working harder usually only raises your trading volume, output count, application count, and working hours, but not necessarily your mathematical expectation. The more you do, the closer you get to the system's average return for ordinary participants; and if the system itself includes transaction costs, platform commissions, and time costs, the average return may well be negative.
So the question isn't "should I work hard," but rather: is what I'm working hard at a near-zero-expectation game?
If the answer is yes, then what you should really be looking for isn't a more diligent knob, but something that changes the expectation: information asymmetry, capability asymmetry, distribution asymmetry, resource asymmetry, brand trust, compounding assets, or simply a less crowded game.
Closing: I Stopped It, But This Isn't a Failure
I shut down live trading, cleared the scripts, state, and API credentials on the cloud server, and kept the local code and data for now. A bit over fifty dollars remained in the wallet—I didn't lose much; this was a small-scale validation in the first place.
Writing this out, I want to make one thing clear: this isn't a failure, it's a successful falsification.
What I got for two days of work is a clear enough answer: using the retail-accessible method of "technical momentum + trend-following" on the BTC 5-minute market, I have not demonstrated a sustainable, tradeable edge. That answer is valuable—it saves me from spending a third day, a tenth day, turning knobs that were never going to budge.
And the infrastructure is a real win: a complete pipeline that can place orders, settle, backtest, deploy to a server, and monitor and alert—those skills transfer to a different battlefield.
A Few Things I Actually Learned
- Always ask "is the sample large enough" first. A +36% finding paired with n = 30 is roughly equivalent to no finding at all. Look at n first, then the return.
- t is more honest than win rate and total profit. Because it compresses "how much earned, how much variance, how many trades" into a single number, specifically designed to separate luck from skill. If t < 2, zip it.
- Small samples reward obsession. The more dimensions, the finer the slicing, the easier it is to find an accidentally positive corner in the noise—this is called multiple comparisons, and it's the breeding ground for self-deception.
- "There's no edge here" is the most expensive and most worth-accepting-early conclusion in quant work. Acknowledging it is far cheaper than continuing to fool yourself.
- Effort itself isn't edge. If the rules, signals, and tools are all public, effort will usually only bring you to the average; what changes expectation is something others don't have.
- The more you do, the closer you get to the truth. In an efficient market, the other half of that sentence is: closer to zero.
This is a post-mortem of a failure. If you're somewhere in a market, platform, or track turning knobs endlessly and can't push t past 2—maybe it's time to stop, expand the sample, and look at that number honestly.
Related Posts
OpenClaw Brings *Her* into the Real World: I Built an AI Companion That Remembers and Gets Things Done
What made *Her* real for me wasn’t a single model—it was OpenClaw. By connecting long-term memory, a permission system, and local execution, it turns AI from “good at conversation” into something that can truly accompany you and take action.
I Built an AI Automation System with OpenClaw That Handles 15 Tasks for Me Every Day
An open-source framework, four AI agents, and a fully automated personal productivity system — from Telegram chat to crypto reports, from English learning recommendations to multi-platform content publishing. This is my real daily routine built with OpenClaw.
Get Notes to Obsidian Importer 2.0 - Note Migration in the All-in AI Era
From flomo to Get Notes, I rebuilt a note sync plugin with AI. Sharing the complete journey of All-in AI development.